

자바 1.8(Java 8)은 자바 언어 역사에서 가장 중요한 업데이트 중 하나로 평가받으며, 특히 람다(Lambda)와 스트림(Stream) API가 도입되면서 자바 언어의 사용성과 생산성이 대폭 향상되었습니다.
특히나, 스트림 API같은 경우에 효율적으로 병렬프로그래밍을 구사할 수 있게됨으로써 자바1.8버전 이상을 사용하시는분들이 더욱 효율적인 코드를 구사할 수 있게되었는데요, 이 글에서는 자바 1.8에서 추가된 람다와 스트림에 대해 알아보고, 각각의 장단점과 성능적인 측면에서의 고려 사항을 설명하는 시간을 가져보도록 하겠습니다.
람다 표현식(Lambda Expression)이란?

람다 표현식은 자바에서 간결하게 함수를 정의하는 방식입니다.
간단히 말해, 람다는 익명 함수(Anonymous Function)를 표현하기 위해 사용되는데, 람다를 통해 코드를 보다 간결하고 직관적으로 작성할 수 있으며, 특히 함수형 인터페이스를 구현하는 데 매우 유용합니다.
예를 들어, 컬렉션의 요소를 처리할 때 람다 표현식을 활용하면 기존의 익명 클래스 작성보다 코드가 훨씬 더 간결해집니다.
예시로, 리스트의 요소를 람다식으로 모두 출력하는 경우는 아래와 같습니다.
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
names.forEach(name -> System.out.println(name));이러한 람다 표현식은 코드의 간결성을 크게 높이며, 콜백 메서드나 이벤트 리스너와 같은 곳에서 특히 유용합니다.
하지만 이러한 장점만 있을 것 같은 람다의 기능에도 몇 가지 단점도 존재하며, 이를 잘 이해하고 사용하는 것이 중요합니다.
람다의 장점
- 간결한 코드: 람다 표현식을 사용하면 코드가 간결해지고 가독성이 높아집니다. 익명 클래스를 작성하는 번거로움이 줄어들며, 특히 콜백 메서드나 이벤트 리스너 같은 곳에서 효율적입니다.
- 함수형 프로그래밍 지원: 자바 1.8부터 함수형 프로그래밍을 부분적으로 지원하면서, 람다는 이러한 패러다임을 활용하는 데 중요한 역할을 합니다. 함수형 인터페이스와 결합하여 강력한 표현력을 제공합니다.
- 지연 평가(Lazy Evaluation): 람다와 스트림을 함께 사용할 때, 연산이 필요할 때까지 지연되는 특성을 가질 수 있어 효율적인 메모리 사용이 가능합니다.
람다의 단점
- 디버깅이 어려움: 람다는 익명 함수이기 때문에 스택 트레이스에서 익명 클래스와 비슷한 이름으로 나타납니다. 따라서 디버깅 시 람다 표현식의 위치를 찾기가 어려울 수 있습니다. 특히, 스택 트레이스가 깊어지면 문제의 원인을 파악하기 어렵습니다.
- 복잡한 로직을 적용할 경우 가독성 저하: 간단한 로직에는 적합하지만, 람다 표현식이 너무 길어지면 오히려 코드의 가독성을 떨어뜨릴 수 있으므로 복잡한 로직은 람다보다는 명시적인 메서드로 분리하는 것이 좋습니다.
- 러닝커브: 람다 표현식은 자바 1.8 이전의 방식과 다르기 때문에, 기존 Java 개발자들이 새로운 문법을 익히는 데 시간이 걸릴 수 있으며, 함수형 인터페이스와 같은 새로운 개념도 함께 이해해야 하므로 초반 학습 곡선이 존재합니다.
익명 함수?
익명 함수(Anonymous Function)란 이름이 없는 함수로, 일반적으로 특정 작업을 일회성으로 수행할 때 사용됩니다.
스트림 API란?
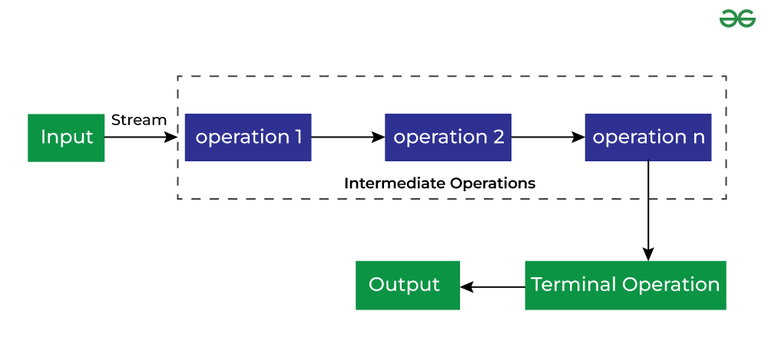
스트림(Stream) API는 자바 1.8에서 도입된 기능으로, 컬렉션의 요소를 처리하는 것을 선언적으로 표현할 수 있도록 도와줍니다. 스트림을 사용하면 데이터를 필터링하고 변환하며 집계하는 등의 작업을 간결하게 표현할 수 있습니다. 스트림은 데이터를 파이프라인 방식으로 처리하며, 중간 연산과 최종 연산으로 나눠집니다.
스트림의 사용 예시는 아래와 같습니다.
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
List<String> filteredNames = names.stream()
.filter(name -> name.startsWith("A"))
.collect(Collectors.toList());
이러한 스트림은 데이터를 읽기 전용으로 처리하며, 한 번 사용된 스트림은 재사용할 수 없습니다.
이러한 특성으로 인해 스트림은 일회성 데이터 처리를 위해 설계되었으며, 연산의 흐름을 직관적으로 표현할 수 있습니다.
스트림의 장점
- 선언적 코드 작성: 스트림 API를 사용하면 데이터를 필터링, 매핑, 축소 등의 작업을 간결하고 선언적으로 작성할 수 있습니다. 복잡한 반복문 대신 간단한 표현식으로 데이터 처리를 정의할 수 있어 가독성과 유지보수성이 높아집니다.
- 병렬 처리 지원: 스트림은 병렬 처리를 위한 parallelStream()메소드를 제공하며, 이를 통해 데이터를 여러 CPU 코어에 분산하여 처리할 수 있어 대용량 데이터 처리에 효과적입니다. 병렬 처리는 스레드를 활용하여 작업을 나누므로, CPU를 최대한 활용할 수 있습니다.
- 지연 연산(Lazy Evaluation): 스트림은 필요할 때까지 연산을 수행하지 않는 지연 특성을 가지고 있어, 불필요한 계산을 방지하고 메모리 사용을 최적화할 수 있습니다. 중간 연산은 최종 연산이 호출될 때까지 실행되지 않기 때문에 효율적인 데이터 처리가 가능합니다.
스트림의 단점
- 성능 오버헤드: 작은 컬렉션을 처리할 때는 스트림을 사용하는 것이 오히려 오버헤드를 발생시킬 수 있습니다. 예를 들어, 리스트의 요소가 적을 때는 스트림의 내부 처리 비용이 반복문을 사용하는 것보다 크기 때문에 성능이 떨어질 수 있습니다. 스트림은 함수 호출과 객체 생성 등의 오버헤드가 있으므로, 작은 데이터셋에서는 단순 반복문보다 느릴 수 있습니다.
- 디버깅의 어려움: 스트림의 파이프라인을 거쳐 데이터가 처리되는 방식은 한눈에 파악하기 어렵습니다. 디버깅 시 각 단계에서 데이터가 어떻게 변화하는지 추적하는 것이 쉽지 않으며, 특정 연산이 제대로 이루어졌는지 확인하기 어렵습니다.
- 메모리 사용량 증가: 스트림은 내부적으로 많은 객체를 생성하므로, 큰 데이터를 처리할 때 메모리 사용량이 증가할 수 있습니다. 특히 잘못된 사용으로 인해 메모리 누수가 발생할 가능성도 있으며, 불필요한 객체 생성은 GC(가비지 컬렉터) 부담을 가중시킬 수 있습니다.
스트림의 고려 사항
1. 작은 컬렉션 vs 큰 컬렉션
- 사이즈가 작은 컬렉션: 작은 크기의 리스트나 컬렉션을 처리할 때는 스트림 대신 반복문(for-loop)을 사용하는 것이 더 나을 수 있습니다. 스트림 API는 내부적으로 함수 호출과 람다 표현식의 오버헤드가 있기 때문에, 작은 데이터셋에서는 오히려 성능이 저하될 수 있습니다.
- 사이즈가 큰 컬렉션: 데이터의 크기가 커질수록 스트림의 장점이 드러납니다. 특히 parallelStream()메소드를 사용하여 멀티 코어에 작업을 분산하면 성능 이점을 얻을 수 있습니다. 다만, 병렬 스트림을 사용할 때는 스레드 간의 컨텍스트 스위칭 비용을 고려해야 합니다. 스레드 간의 경쟁이 심한 환경에서는 오히려 성능이 떨어질 수 있습니다.
2. 반복 vs 스트림
- 반복문(for-loop): 기존 for-loop은 성능적으로 단순작업이나, 컬렉션의 사이즈가 작은 경우 매우 이점이 강합니다. 특히 단순한 반복과정에서 for-loop은 스트림에 비해 메모리 사용과 실행 속도 면에서 유리하며, JVM 최적화가 용이하여, 스트림의 오버헤드 없이 간단하게 작업을 처리할 수 있습니다.
- 스트림(stream): 코드 가독성과 유지보수성 측면, 컬렉션의 사이즈가 매우 클 경우에 스트림은 더 좋은 퍼포먼스를 낼 수 있습니다. 예를 들어, 컬렉션에서 데이터를 필터링하거나 매핑할 때는 스트림을 사용하면 더 간결하게 표현할 수 있습니다. 다만 성능이 중요한 상황에서는 코드의 상황에 따라 반복문을 사용할지, stream을 사용할 지에 대한 적절한 선택을 필요로 합니다..
3. 중간 연산과 최종 연산의 비용
- 중간 연산(map, filter 등): 중간 연산은 Lazy Evaluation 특성을 가지므로, 실제 연산이 필요할 때만 수행됩니다. 다만, 중간 연산이 많이 겹칠 경우 각 연산에서 람다 호출이 중첩되어 성능 저하가 발생할 수 있습니다. 특히 여러 번의 필터링과 매핑이 겹쳐지면, 각 단계에서 불필요한 객체가 생성될 수 있어 성능이 떨어질 수 있습니다.
- 최종 연산(forEach, collect 등): 최종 연산은 스트림 파이프라인을 끝내고 결과를 생성합니다. 최종 연산의 성능은 데이터 크기와 중간 연산의 수에 따라 영향을 받을 수 있습니다. 예를 들어, 여러 번의 filter와 map 연산 후 collect를 수행하면, 그동안의 연산이 모두 한 번에 실행되므로 메모리 사용량이 증가할 수 있습니다. 이로 인해 대규모 데이터 처리 시 성능이 저하될 수 있으므로, 중간 연산의 수를 최소화하는 것이 중요합니다.
람다와 스트림, 반복문 비교
스트림과 람다 표현식을 사용한 코드와 기존 for문을 사용한 코드를 비교하여 설명하겠습니다.
1. 리스트 순회 예시
- 기존 for문 사용
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
for (String name : names) {
System.out.println(name);
}- 람다 표현식 사용
names.forEach(name -> System.out.println(name));람다 표현식을 사용하면 코드가 더 간결해지며, 반복문에 비해 명확하게 요소를 처리하는 의도를 표현할 수 있습니다. 하지만 단순한 반복 작업에서는 기존 for문이 성능 면에서 더 유리할 수 있습니다.
2. 필터링과 매핑 예시
- 기존 for문 사용
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
List<String> filteredNames = new ArrayList<>();
for (String name : names) {
if (name.startsWith("A")) {
filteredNames.add(name.toUpperCase());
}
}- 스트림 사용
List<String> filteredNames = names.stream()
.filter(name -> name.startsWith("A"))
.map(String::toUpperCase)
.collect(Collectors.toList());스트림을 사용하면 데이터를 필터링하고 매핑하는 과정을 선언적으로 표현할 수 있어, 코드의 가독성이 크게 향상됩니다. 하지만 작은 데이터셋에서는 기존 for문 방식이 빠를 수 있습니다.
3. 배열로 변환 예시
- 기존 for문 사용
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
String[] namesArray = new String[names.size()];
for (int i = 0; i < names.size(); i++) {
namesArray[i] = names.get(i);
}- 스트림 사용
String[] namesArray = names.stream().toArray(String[]::new);스트림을 사용하면 배열로 변환하는 작업이 매우 간결해집니다. 그러나 단순 변환 작업에서는 for문이 더 빠를 수 있고, 스트림의 내부 오버헤드로 인해 성능이 저하될 가능성이 있음을 인지하여야 합니다.
List 노드 수에 따른 for문과 스트림의 성능 비교
리스트의 노드 수가 증가함에 따라 for문과 스트림(Stream) 간의 성능 차이는 두드러지게 나타납니다.
특히 스트림의 parallelStream() 메소드를 사용했을 때 병렬 처리의 효과가 명확히 드러나며, 이로 인해 대용량 데이터를 처리할 때 성능의 이점을 얻을 수 있음을 알 수 있습니다. 하지만 리스트가 작은 경우에는 스트림보다는 기존의 반복문을 사용하는 것이 더 효율적임이 나타나는 성능 비교 표입니다.
먼저, 성능테스트의 결과물부터 보여드리겠습니다.
아래는 리스트의 크기에 따른 for문, 순차 스트림(Stream), 병렬 스트림(Parallel Stream)의 성능을 비교한 입니다:
| 리스트 크기 (노드 수) | for문 (ms) | 일반 스트림 (Stream) (ms) | 병렬 스트림 (Parallel Stream) (ms) |
| 100 | 0 | 13 | 28 |
| 1,000 | 0 | 0 | 4 |
| 10,000 | 0 | 0 | 3 |
| 100,000 | 2 | 2 | 18 |
| 1,000,000 | 7 | 12 | 2 |
| 10,000,000 | 68 | 10 | 5 |
| 100,000,000 | 698 | 92 | 25 |
| 150,000,000 | 1025 | 156 | 31 |
위 표에서 볼 수 있듯이, 리스트의 크기가 작을 때는 for문이 스트림보다 항상 더 빠름을 알 수 있습니다.
이는 스트림의 내부 오버헤드와 함수 호출 비용 때문이지만, 데이터의 크기가 커질수록 일반 스트림과, 병렬 스트림 (Parallel Stream)이 더 좋은 성능을 보여줌을 나타냅니다.
병렬 스트림은 여러 코어에 작업을 나누어 처리하기 때문에, CPU 코어가 많을수록 더 큰 성능 이점을 볼 수 있습니다.
병렬 처리의 효율성
병렬 스트림을 사용할 때의 성능 향상은 CPU 코어 수와 작업의 특성에 따라 달라집니다.
예를 들어, 멀티코어 시스템에서 큰 데이터셋을 처리할 때 병렬 스트림을 사용하면 각 코어가 독립적으로 작업을 수행함으로써 전체 처리 시간이 줄어듭니다.
그러나 병렬 스트림은 스레드 관리 및 컨텍스트 스위칭 비용이 발생하므로, 데이터셋이 작거나 병렬 작업이 비효율적인 경우 오히려 성능이 떨어질 수 있습니다.
병렬 스트림의 주요 특징과 고려 사항
- 멀티코어 활용: 병렬 스트림은 자바 ForkJoinPool을 사용하여 데이터를 여러 스레드에 분산합니다. 이로 인해 CPU 코어가 많을수록 더 큰 성능 향상을 볼 수 있습니다.
- 컨텍스트 스위칭 비용: 스레드 간에 작업을 분산할 때는 컨텍스트 스위칭 비용이 발생합니다. 이 비용이 크면 병렬 처리의 이점이 상쇄될 수 있습니다.
- 데이터 일관성 보장: 병렬로 데이터를 처리할 때는 데이터 일관성 문제를 고려해야 합니다. 적절한 동기화가 이루어지지 않으면 데이터가 잘못 처리될 수 있습니다.
ForkJoinpool?ForkJoinPool은 자바의 병렬 프로그래밍 프레임워크로, 작업을 작은 단위로 나누어 병렬로 처리하고 결과를 합치는 방식(divide-and-conquer)을 사용하여 효율적으로 연산을 수행할 수 있도록 돕는 스레드 풀입니다. 자바 7에서 도입되었으며, 특히 자바 8의 병렬 스트림(parallel streams)에서 내부적으로 사용됩니다.
성능 테스트 코드 예시
다음은 리스트의 요소를 반복문, 스트림, 병렬 스트림으로 처리하여 성능을 비교하는 코드입니다:
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.concurrent.TimeUnit;
public class main {
public static void main(String[] args) {
int[] sizes = {100, 1000, 10_000, 100_000, 1_000_000, 10_000_000, 100_000_000, 150_000_000};
for (int size : sizes) {
List<Integer> numbers = new ArrayList<>();
Random random = new Random();
for (int i = 0; i < size; i++) {
numbers.add(random.nextInt(1000));
}
// For loop 테스트
long startTime = System.nanoTime();
long sum = 0;
for (int number : numbers) {
sum += number;
}
long endTime = System.nanoTime();
long forTime = TimeUnit.NANOSECONDS.toMillis(endTime - startTime);
// Stream 테스트 (일반 Stream)
startTime = System.nanoTime();
sum = numbers.stream().mapToInt(Integer::intValue).sum();
endTime = System.nanoTime();
long streamTime = TimeUnit.NANOSECONDS.toMillis(endTime - startTime);
// Stream 테스트 (병렬 Stream)
startTime = System.nanoTime();
sum = numbers.parallelStream().mapToInt(Integer::intValue).sum();
endTime = System.nanoTime();
long parallelTime = TimeUnit.NANOSECONDS.toMillis(endTime - startTime);
System.out.printf("Size: %d | For loop: %d ms | Stream: %d ms | Parallel Stream: %d ms% \n",
size, forTime, streamTime, parallelTime);
}
}
}위는 반복문, 순차스트림, 병렬스트림에 대한 성능 비교 테스트코드입니다.
이에대한 결과는 아래와 같습니다 (맥북 m1프로 16in RAM 16GB기준).
Size: 100 | For loop: 0 ms | Stream: 13 ms | Parallel Stream: 28 ms
Size: 1000 | For loop: 0 ms | Stream: 0 ms | Parallel Stream: 4 ms
Size: 10000 | For loop: 0 ms | Stream: 0 ms | Parallel Stream: 3 ms
Size: 100000 | For loop: 2 ms | Stream: 2 ms | Parallel Stream: 18 ms
Size: 1000000 | For loop: 7 ms | Stream: 12 ms | Parallel Stream: 2 ms
Size: 10000000 | For loop: 68 ms | Stream: 10 ms | Parallel Stream: 5 ms
Size: 100000000 | For loop: 698 ms | Stream: 92 ms | Parallel Stream: 25 ms
Size: 150000000 | For loop: 1025 ms | Stream: 156 ms | Parallel Stream: 31 ms
결과는 실행 환경에 따라 다를 수 있지만, 일반적으로 데이터셋이 클수록 병렬 스트림의 성능이 눈에 띄게 향상되는 것을 볼 수 있습니다.
(사실 Size를 유의미하게 1억5천만보다 훨씬 키운 값을 보여드리고싶었는데, 램이 적어 스왑디스크를 많이 사용하는이슈가 발생하는바람에 신빙성있는 자료를 제공하기위해선 이정도가 한계였습니다..)
끝으로

반복문, 람다 표현식과 스트림에대한 포스팅이 마무리되었습니다.
자바 1.8의 람다 표현식과 스트림 API는 자바 개발자들이 더 간결하고 선언적인 코드 작성을 가능하게 해주었고, 병렬 처리를 쉽게 구현할 수 있도록 도와주었으나, 오히려 작은 데이터셋이나 간단한 작업에서는 성능상의 불리함이 있을 수 있기에 적절한 상황에서 적합한 구문을 사용하는 것이 중요합니다.
또한, 람다와 스트림을 사용할 때는 코드의 가독성과 유지보수성뿐만 아니라 성능적인 고려도 함께 해야 하며, 데이터의 크기와 복잡성에 따라 가장 적합한 방법을 사용해가며 프로그래밍을 진행하는것이 아주 중요할것같습니다.
이상으로 블로그포스팅을 마치며,
혹여나 이 포스팅에서 중요한 정보가 빠졌거나, 틀린 정보를 지적해주신다면 감사히 받겠습니다!
출처
- Java 8 Official Documentation
- Baeldung - Java 8
- GeeksforGeeks - Java 8 Features
- Effective Java by Joshua Bloch
- Java 8 in Action by Raoul-Gabriel Urma, Mario Fusco, Alan Mycroft
'Language > Java' 카테고리의 다른 글
| [Java] 제네릭 (Generic) (3) | 2024.10.12 |
|---|---|
| [Java] 인터페이스 (Interface) + abstract class와의 차이 (1) | 2024.10.12 |
| [Java] 추상 클래스 (Abstract class) (0) | 2024.08.22 |